
Dans notre article précédent, nous avons parlé de Pandas, ses avantages ainsi que ses cas d'usage.
Aujourd’hui, nous allons faire une démonstration pratique, pour vous permettre de prendre en main Pandas.
 Xarala Academy
Xarala Academy
Comment installer Pandas?
La façon la plus simple d’installer non seulement Panda, mais aussi Python et ses bibliothèques les plus populaires (IPython, NumPy, Matplotlib, ...) est d’utiliser Anaconda, une distribution Python multiplateforme (Linux, macOS, Windows) pour l’analyse de données et le calcul scientifique.

Installer Pandas à l'aide d'Anaconda
Rendez-vous sur le site et cliquez sur l'icône "Download". Merci de bien choisir votre système d’exploitation (MacOS, Windows ou Linux).
Cliquez sur le fichier exécutable, puis sur le bouton continuer.
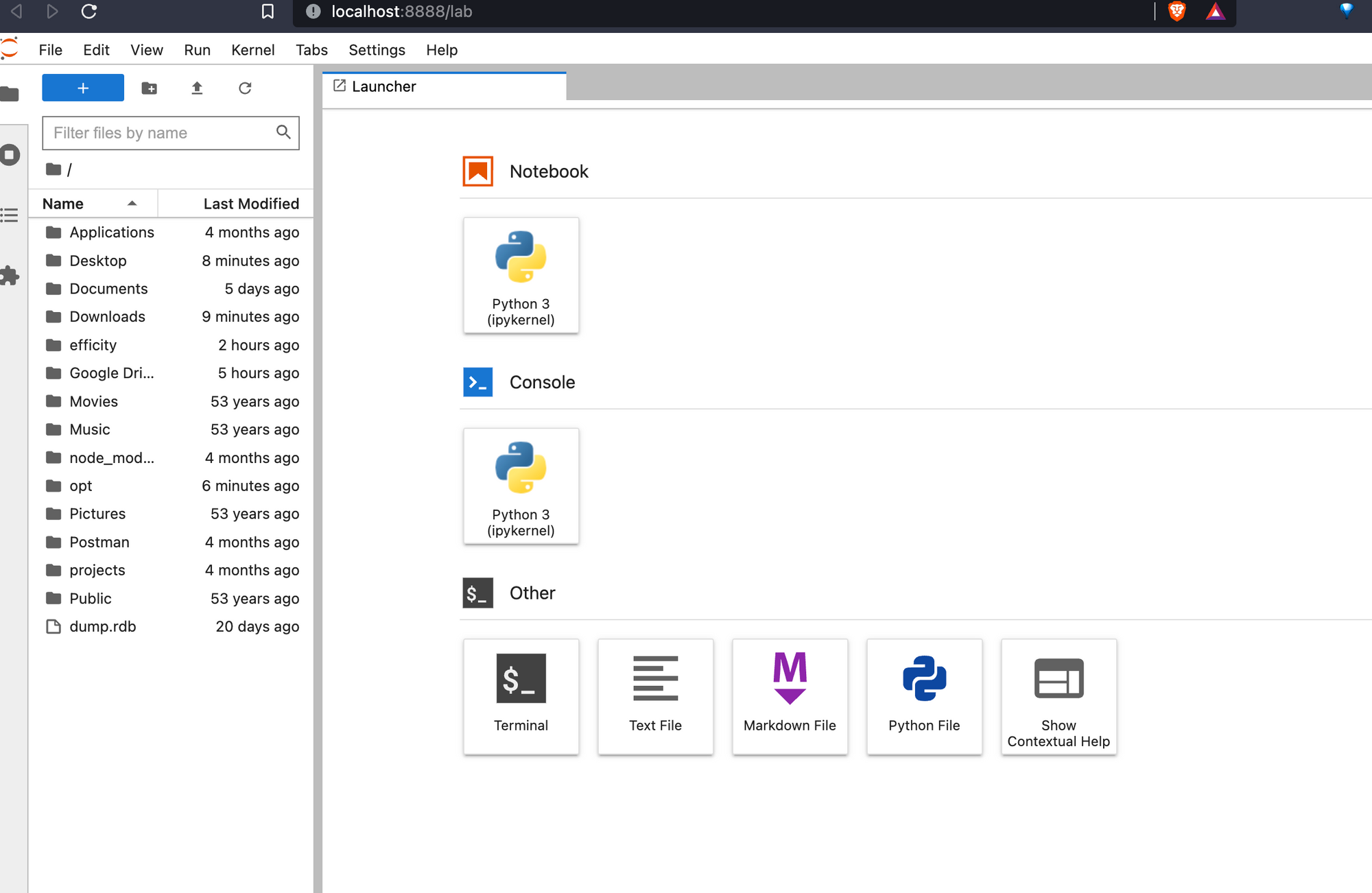
Démarrer avec JupyterLab
Pour démarrer avec JupyterLab, tapez sur votre terminal ❯ jupyter lab patientez quelques secondes, Jupyter va ouvrir une nouvelle fenêtre de navigation sur http://localhost:8888/lab.
Créer un nouveau Notebook Python dans JupyterLab.
Importer pandas et faire un petit test.

Ensuite, il faut charger le jeu de données.
Pour charger le jeu de données, nous avons plusieurs options basées sur le format de la source. Ici, le format de la source est csv, donc nous utiliserons la méthode Pandas read_csv(), qui lira le csv, et chargera l'ensemble des données dans le Data Frame.
Rappel: Le Data Frame de Pandas est une structure de données tabulaire bidimensionnelle, potentiellement hétérogène, de taille variable, avec des axes étiquetés (lignes et colonnes). Les opérations arithmétiques s'alignent sur les étiquettes des lignes et des colonnes. Elle peut être considérée comme un dictionnaire - comme un conteneur pour les objets de la série. Il s'agit de la principale structure de données des Pandas.
import pandas as pd
df = pd.read_csv("./datasets.csv")Ici, vous pouvez télécharger ce fichier et le placer dans le dossier de votre notebook.

Aller plus loin
Dans la suite de cet article, nous allons travailler avec l'ensemble de données sur le fichier mentionné ci-dessus. La prochaine chose à faire est de jeter un coup d'œil à notre DataFrame. Nous pouvons vérifier les n premières entrées avec la fonction head. Si n n'est pas fourni, nous verrons les 5 premières lignes par défaut.
df.head()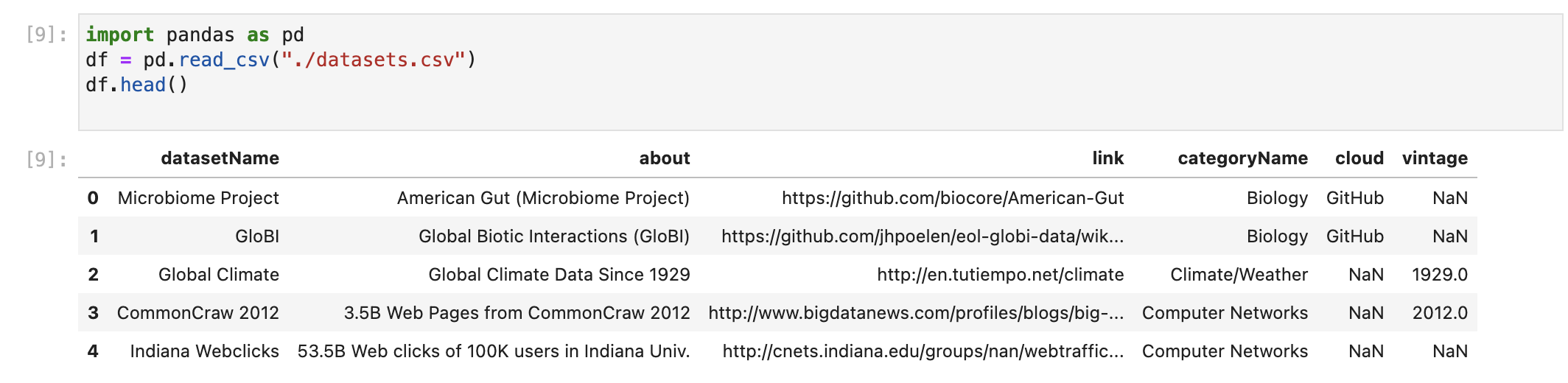
À première vue, tout semble correct. Nous pouvons également vérifier les dernières entrées de l'ensemble avec la fonction tail.
df.tail()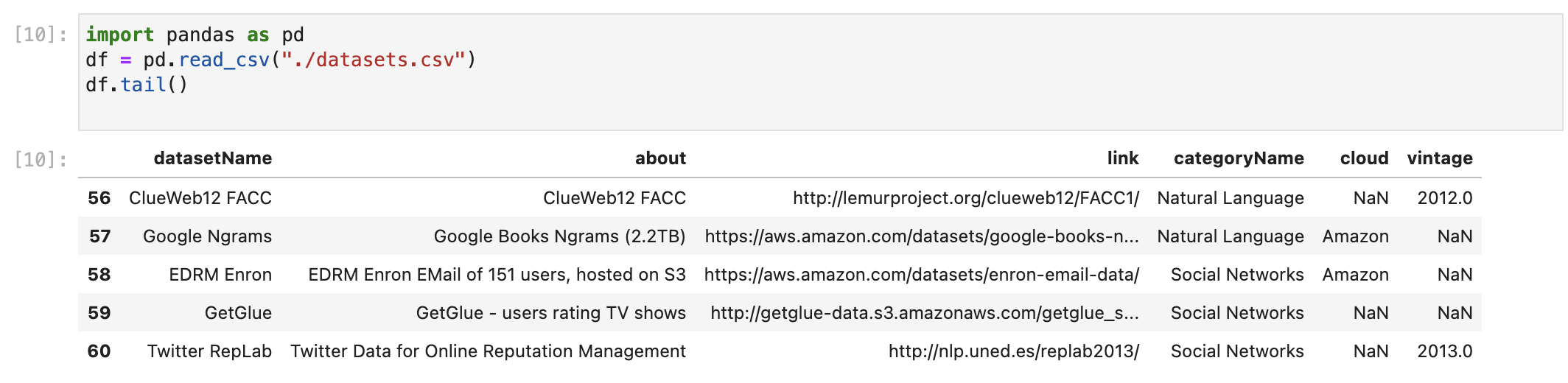
Ensuite, vérifions les dimensions de nos données en utilisant l'attribut shape.
df.shape
Il renvoie un tuple contenant le nombre de lignes et de colonnes. Notre DataFrame comporte 61 lignes et 6 colonnes, ou caractéristiques.
Pour continuer, nous pouvons afficher un résumé de l'ensemble des données avec la fonction info.
df.info()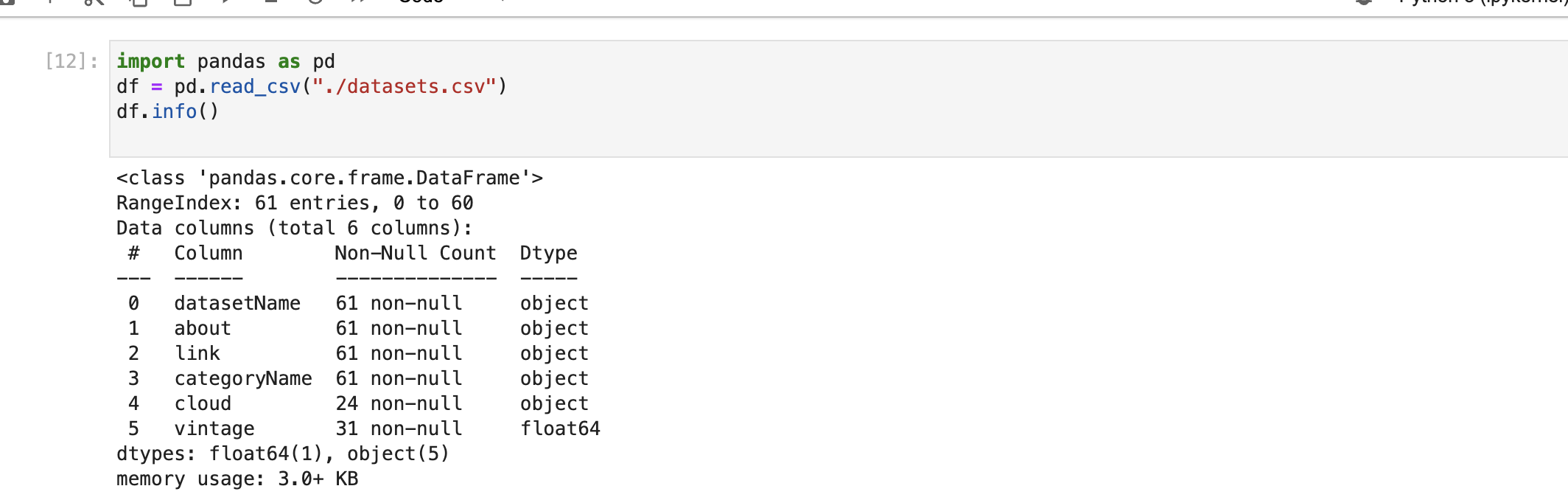
Il nous montre des informations utiles sur le DataFrame, comme les noms des colonnes, les valeurs non nulles, les dtypes et l'utilisation de la mémoire. À partir de ce résumé, nous pouvons observer que certaines colonnes ont des valeurs manquantes, un sujet que nous verrons plus tard.
La fonction suivante nous donnera quelques statistiques descriptives sur l'ensemble de données.
df.describe()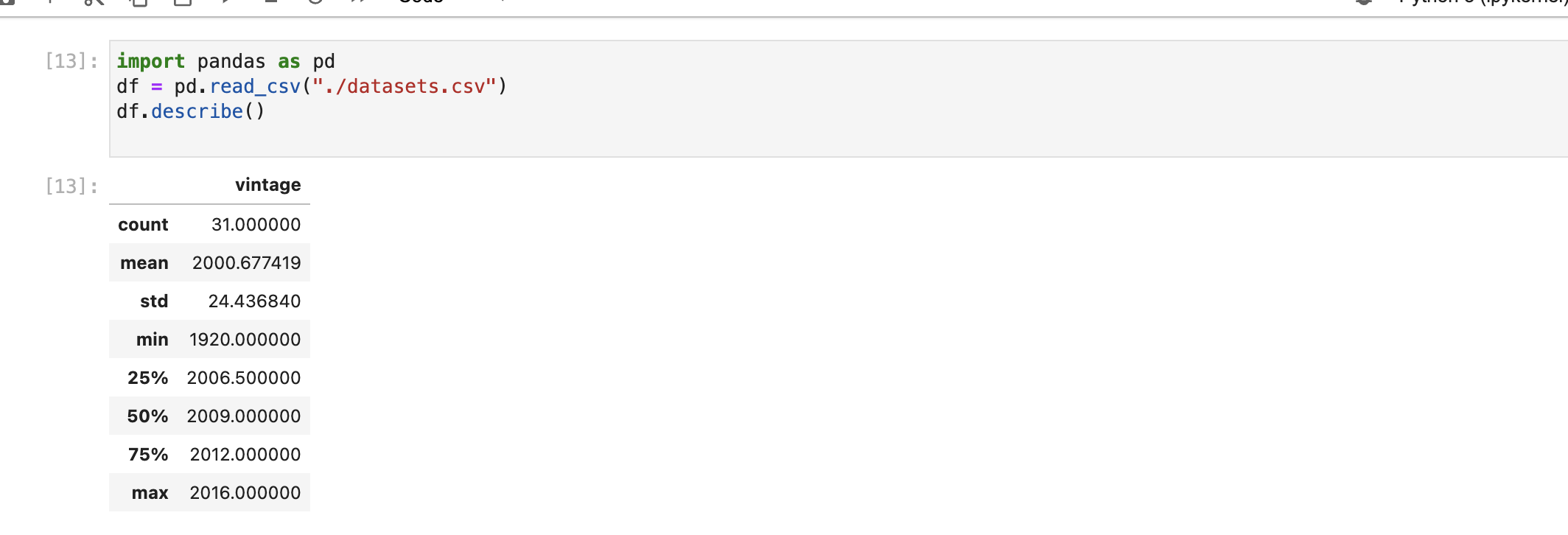
Cette fonction affiche le nombre, la moyenne, la médiane, l'écart type, les quartiles supérieurs et inférieurs, ainsi que les valeurs minimales et maximales pour chaque caractéristique. Notez qu'elle n'affiche que les données relatives aux caractéristiques numériques (colonnes dont le type de données est int ou float).
Nous pouvons calculer les valeurs minimales et maximales ainsi que la moyenne.
# la moyenne
df["vintage"].mean()
# maximale
df["vintage"].max()
# minimal
df["vintage"].min()Visualisation de données avec Python.
Dans notre prochain article, nous allons vous montrer comment visualiser les données avec Python.
Vous avez aimé cet article ? Rejoignez le Bootcamp
Ce tutoriel devrait suffire à vous faire découvrir la puissance de Pandas. Si vous voulez aller plus loin, inscrivez-vous à notre prochaine cohorte.





